A/B Testing
Large Language Models (LLMs) like GPT, Gemini, Claude, and LaMDA are rapidly evolving, each with its strengths and weaknesses. A/B testing allows us to compare their performance in different use cases and identify the most suitable model for specific tasks. Here's a breakdown for research exploration:
Use Cases for A/B Testing:
Content Generation:
- Task: Generate product descriptions, blog posts, or marketing copy.
- Metrics: Conversion rates, user engagement (time spent reading, clicks), customer satisfaction surveys about content quality.
- Hypothesis: GPT, known for creative text formats, might outperform others in generating engaging content. LaMDA, with its focus on factual language, might be better for product descriptions.
Machine Translation:
- Task: Translate text from one language to another for documents, websites, or live chat conversations.
- Metrics: Translation accuracy (measured by human evaluation or automated tools), fluency and naturalness of the translated text.
- Hypothesis: Models trained on specific language pairs might perform better. Claude, known for its multilingual capabilities, could be a strong contender.
Question Answering:
- Task: Answer user queries on a company website, in a customer support chatbot, or for internal knowledge management systems.
- Metrics: Accuracy of answers, user satisfaction with answer clarity and helpfulness, time taken to provide answers.
- Hypothesis: Gemini, with its focus on context and data exploration, might excel at answering complex questions that require in-depth understanding. LaMDA, trained on dialogue, could be good for conversational question answering.
Code Generation:
- Task: Generate code snippets based on natural language descriptions or complete small coding tasks.
- Metrics: Code functionality, efficiency, adherence to coding best practices.
- Hypothesis: GPT, with recent advancements in code generation, could be a strong candidate. However, human evaluation of code quality is crucial.
Creative Text Formats:
- Task: Generate poems, scripts, musical pieces, or other creative text formats based on user prompts.
- Metrics: Human evaluation of creativity, originality, and adherence to the prompt's style and theme.
- Hypothesis: GPT, known for its creative text generation capabilities, might be well-suited for these tasks.
Challenges and Considerations:
- Data Bias: LLMs can inherit biases from their training data. Ensure the testing data reflects your target audience and avoids perpetuating biases.
- Human Evaluation: While automated metrics are helpful, human evaluation is crucial for tasks like content quality, code functionality, and creative text formats.
- Usability and Integration: Consider the ease of use and integration of each LLM into your existing systems when making a final decision.
Limited Research Availability:
Unfortunately, due to the constantly evolving nature of LLMs and the proprietary nature of some models, publicly available research on A/B testing them across diverse use cases is scarce.
However, here are some resources to kickstart your research:
- Academic Papers: Search for papers on LLM evaluation and comparison, even if they don't directly involve A/B testing. Terms like "large language model evaluation," "comparative analysis of LLMs," or "A/B testing for NLP tasks" might be helpful. (https://arxiv.org/)
- Blog Posts and Industry Reports: Tech blogs and industry reports from companies like OpenAI or Google AI might shed light on the strengths and weaknesses of specific LLMs in different tasks.
- Case Studies: Look for case studies where companies have implemented LLMs for specific tasks. You might glean insights into how they evaluated different models and the factors they considered when making their choice.
By conducting thorough A/B testing and considering the specific needs of your use case, you can identify the LLM that delivers the most optimal performance for your project. As the field of LLM research continues to evolve, expect more resources and testing data to become available in the future.
No matter your use case, don't blindly implement LLMs like GPT-4, Llama 2, or Claude - A/B test them.
It will take some experimentation to find the right model for your purpose and context. There are even differences between versions of a single model — GPT-4 has a world of new capabilities vs. its predecessor GPT-3.5, but its slower speed and higher cost may make it a less optimal fit for certain use cases.
Below is a sample dataset that could be gathered through A/B testing various LLMs like GPT, Gemini, Claude, and LaMDA across different use cases. This hypothetical data includes various metrics such as response accuracy, user engagement, and satisfaction scores.
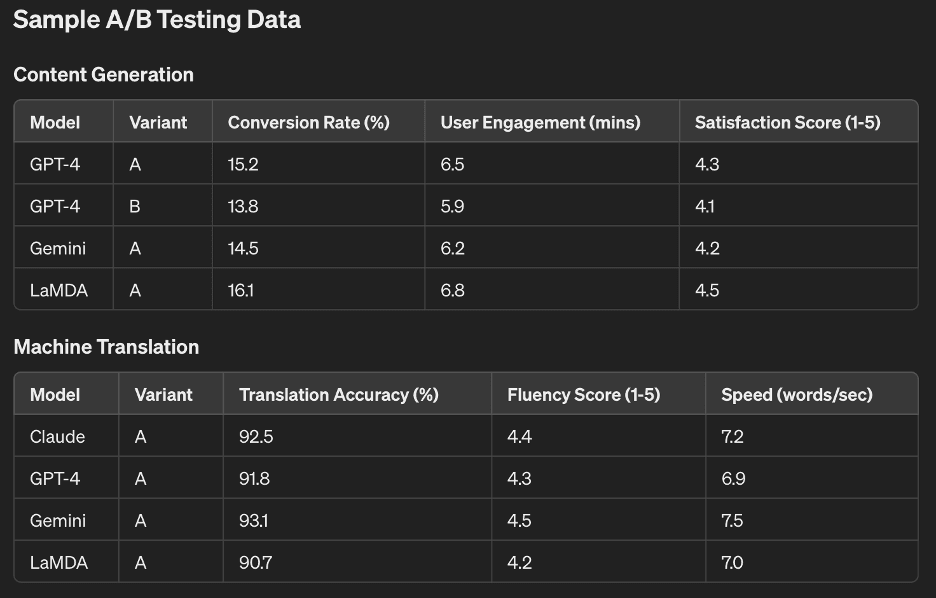
Sample A/B Testing Data
Content Generation
| Model | Variant | Conversion Rate (%) | User Engagement (mins) | Satisfaction Score (1-5) |
|---|---|---|---|---|
| GPT-4 | A | 15.2 | 6.5 | 4.3 |
| GPT-4 | B | 13.8 | 5.9 | 4.1 |
| Gemini | A | 14.5 | 6.2 | 4.2 |
| LaMDA | A | 16.1 | 6.8 | 4.5 |
Machine Translation
| Model | Variant | Translation Accuracy (%) | Fluency Score (1-5) | Speed (words/sec) |
|---|---|---|---|---|
| Claude | A | 92.5 | 4.4 | 7.2 |
| GPT-4 | A | 91.8 | 4.3 | 6.9 |
| Gemini | A | 93.1 | 4.5 | 7.5 |
| LaMDA | A | 90.7 | 4.2 | 7.0 |
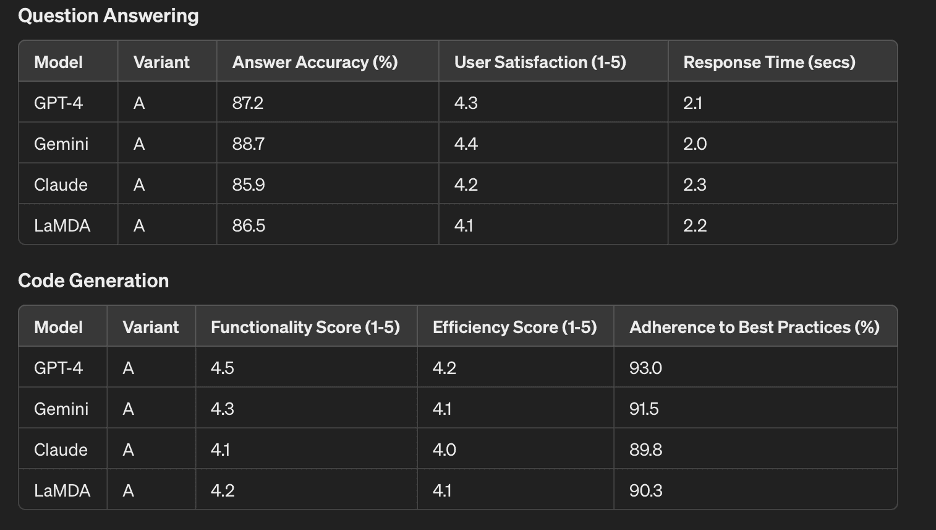
Question Answering
| Model | Variant | Answer Accuracy (%) | User Satisfaction (1-5) | Response Time (secs) |
|---|---|---|---|---|
| GPT-4 | A | 87.2 | 4.3 | 2.1 |
| Gemini | A | 88.7 | 4.4 | 2.0 |
| Claude | A | 85.9 | 4.2 | 2.3 |
| LaMDA | A | 86.5 | 4.1 | 2.2 |
Code Generation
| Model | Variant | Functionality Score (1-5) | Efficiency Score (1-5) | Adherence to Best Practices (%) |
|---|---|---|---|---|
| GPT-4 | A | 4.5 | 4.2 | 93.0 |
| Gemini | A | 4.3 | 4.1 | 91.5 |
| Claude | A | 4.1 | 4.0 | 89.8 |
| LaMDA | A | 4.2 | 4.1 | 90.3 |
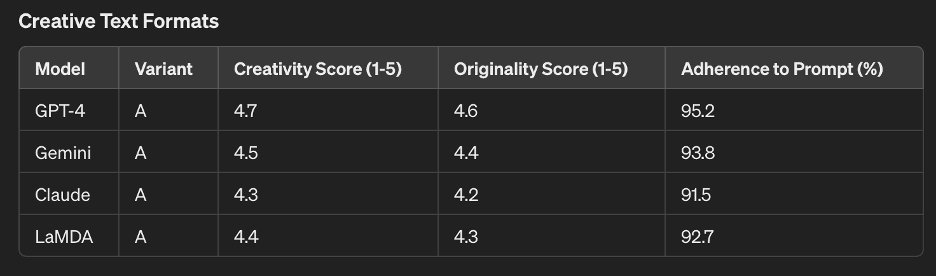
Creative Text Formats
| Model | Variant | Creativity Score (1-5) | Originality Score (1-5) | Adherence to Prompt (%) |
|---|---|---|---|---|
| GPT-4 | A | 4.7 | 4.6 | 95.2 |
| Gemini | A | 4.5 | 4.4 | 93.8 |
| Claude | A | 4.3 | 4.2 | 91.5 |
| LaMDA | A | 4.4 | 4.3 | 92.7 |
Explanation of Metrics
- Conversion Rate: The percentage of users who completed a desired action (e.g., clicked a link, made a purchase) after interacting with the generated content.
- User Engagement: The average amount of time users spent interacting with the content.
- Satisfaction Score: User-rated satisfaction on a scale from 1 to 5, where 5 indicates highest satisfaction.
- Translation Accuracy: The percentage of translations that were correct as evaluated by human judges or automated tools.
- Fluency Score: A score from 1 to 5 indicating how natural and fluent the translated text sounded.
- Speed: The number of words translated per second.
- Answer Accuracy: The percentage of questions answered correctly.
- Response Time: The average time taken to generate an answer.
- Functionality Score: A score from 1 to 5 indicating how well the generated code performed its intended function.
- Efficiency Score: A score from 1 to 5 indicating the efficiency of the generated code.
- Adherence to Best Practices: The percentage of code that followed established best practices.
- Creativity Score: A score from 1 to 5 indicating the creativity of the generated text.
- Originality Score: A score from 1 to 5 indicating how original the generated text was.
- Adherence to Prompt: The percentage of generated content that closely followed the given prompt.
This dataset provides a comprehensive overview of how different LLMs perform across various tasks and metrics, enabling organizations to make informed decisions through A/B testing.
Here is a detailed explanation of how each of these metrics is measured during A/B testing for LLMs:
Content Generation
- Conversion Rate
- Measurement: The conversion rate is calculated by dividing the number of users who completed a desired action (e.g., clicked a link, made a purchase) by the total number of users who saw the content, then multiplying by 100 to get a percentage. This can be tracked using analytics tools like Google Analytics, Mixpanel, or custom backend logging.
- Formula: [\text{Conversion Rate (%)} = \left( \frac{\text{Number of Conversions}}{\text{Total Number of Visitors}} \right) \times 100]
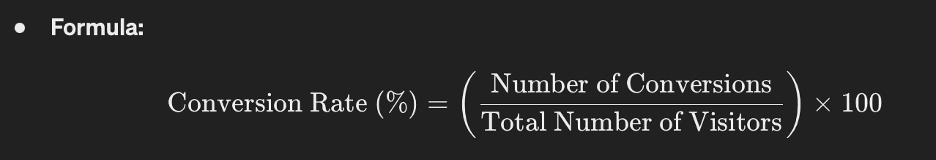
User Engagement
- Measurement: User engagement is typically measured by tracking the average time users spend interacting with the content. This can be done using web analytics tools that provide session duration metrics.
- Tools: Google Analytics, Hotjar, Mixpanel.
Satisfaction Score
- Measurement: User satisfaction scores are collected through surveys or feedback forms where users rate their satisfaction on a scale from 1 to 5. This can be done using tools like SurveyMonkey, Qualtrics, or embedded feedback widgets.
- Tools: SurveyMonkey, Qualtrics, custom feedback forms.
Machine Translation
Translation Accuracy
- Measurement: Translation accuracy is assessed by comparing the translated text to a reference translation. This can be done through human evaluation or automated tools that calculate metrics like BLEU (Bilingual Evaluation Understudy) score, METEOR (Metric for Evaluation of Translation with Explicit ORdering), or TER (Translation Edit Rate).
- Metrics: BLEU, METEOR, TER.
Fluency Score
- Measurement: Fluency is typically rated by human evaluators who assess how natural and grammatically correct the translated text sounds, usually on a scale from 1 to 5.
- Tools: Human evaluators, linguistic experts, MT evaluation platforms.
Speed
- Measurement: Speed is measured by calculating the number of words translated per second. This can be done by tracking the time taken to translate a given text and dividing the total number of words by the time in seconds.
- Formula: [\text{Speed (words/sec)} = \frac{\text{Total Number of Words}}{\text{Total Time in Seconds}}]
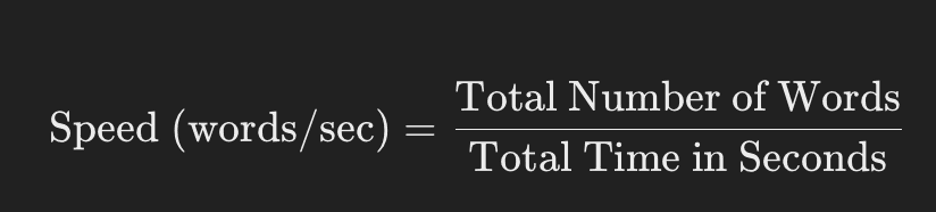
Question Answering
Answer Accuracy
- Measurement: Answer accuracy is determined by comparing the generated answers to a set of correct answers. This can be done through human evaluation or automated systems that check for correctness.
- Metrics: Exact Match (EM), F1 score.
Response Time
- Measurement: Response time is tracked by measuring the time taken from when a query is submitted to when the answer is generated. This can be logged using backend systems.
- Tools: Custom backend logging, performance monitoring tools.
Code Generation
Functionality Score
- Measurement: Functionality is assessed by testing whether the generated code performs its intended function correctly. This is usually done through unit tests or by running the code and verifying the output.
- Tools: Automated testing frameworks (e.g., JUnit, PyTest), human review.
Efficiency Score
- Measurement: Efficiency is evaluated based on the performance of the generated code, such as its execution time and resource usage. Profiling tools can be used to measure these aspects.
- Tools: Profiling tools (e.g., cProfile for Python, JProfiler for Java).
Adherence to Best Practices
- Measurement: This is assessed by reviewing the code against a set of coding best practices and guidelines. Tools like linters and static code analysis can help automate this process.
- Tools: Linters (e.g., ESLint, Pylint), static code analysis tools (e.g., SonarQube).
Creative Text Formats
Creativity Score
- Measurement: Creativity is typically rated by human evaluators who assess how original and imaginative the generated text is. This is done on a scale from 1 to 5.
- Tools: Human evaluators, crowdsourcing platforms (e.g., Amazon Mechanical Turk).
Originality Score
- Measurement: Originality is measured by checking for plagiarism and comparing the generated text to existing works. Tools like Turnitin or Copyscape can be used for this purpose.
- Tools: Plagiarism detection tools (e.g., Turnitin, Copyscape).
Adherence to Prompt
- Measurement: Adherence to prompt is evaluated by checking how well the generated content aligns with the given prompt. This is typically rated by human evaluators.
- Tools: Human evaluators, rubric-based assessments.
By systematically measuring these metrics, organizations can effectively conduct A/B testing to evaluate the performance of different LLMs and make informed decisions based on data-driven insights.
The need to A/B test different models, then, is obvious. If we care about the success and impact of a chosen model on business outcomes (as measured by defined metrics), an A/B test is our gold-standard tool for isolating the causal impact of different LLMs from other external factors.
Offline evaluation isn't enough. It all too often fails to correlate with our actual target business metrics (and can be prone to overfitting), so running online experiments in production becomes the necessity.
Every company will soon be an AI company. There's never been a lower bar for building AI. Where even simple AI deployments previously required an exclusive level of expertise - CS PhDs, data architects, Netflix alumni types - any company can now publish AI applications with the simplest of inputs: human sentence prompts.
But as the cost of deploying AI models goes to zero, companies are lost navigating the choices between models. Already, AI teams need to decide:
- Should we pay up for proprietary OpenAI/Google Bard models or use open source models?
- Is a model tailored to my [healthcare/finance/media] vertical better than a base foundational model?
- Will different prompts improve the performance of these models?
Every company can now deploy models, but winning companies can evaluate models. A cursory examination of top AI practices like Amazon, Netflix, Airbnb reveals the gold standard for evaluation: an obsession with streamlined evaluation via AB testing on business metrics.
The only relevant measurements are customers and business metrics
Winning AI teams evaluate models the same way they evaluate the business. They use business metrics like revenue, subscriptions, and retention. But today's MLOps tools instead lean on proxy metrics measured in offline simulations and historic datasets. Leadership teams must take a leap of faith that simulations will translate to real life.
These simulations rarely predict business impact. Decades of studies from Microsoft, Amazon, Google, and Airbnb reveal an inescapable reality that 80% of AI models will fail to move business metrics, despite glowing performances in simulation. There are plenty of reasons why these simulations don't hold up, from data drift to mismatched historical periods or proxy metrics not translating to business metrics.
The gold standard for model evaluation is randomized control trials, measuring business metrics. Winning AI strategies connect traditional MLOps to the live production environment and core analytics infrastructure. Put simply, enterprise AI needs enterprise AB experimentation.
90% of experimentation workflows are manual
Legacy commercial experimentation technology is not ready for AI workloads. These offerings were built for marketing websites and click metrics, and not for AI model hosting services and business metrics. At a minimum, AI-ready experimentation infrastructure needs the following:
- Native integrations with data clouds like Snowflake, Databricks, BigQuery, and Redshift. These are where business metrics are defined, the same ones powering reports to the CFO.
- Native integrations with modern AI stacks and model hosting services. Legacy experimentation tools tightly couple marketing-oriented setup workflows like WYSIWYG visual editors, preventing easy integration with the best AI infrastructure.
- Enterprise-grade security that keeps sensitive data within customer's clouds. Experimentation requires a rich set of data sources, and the old world of egressing huge volumes of PII to 3rd parties incurring security risks doesn't work.
- Statistical rigor and analytical horsepower to handle the volume of AI models, business metrics, and deep-dives that exist in an enterprise. Any experimentation tool that forces analysts to manually write code in Jupyter notebooks and curate reports in Google Docs will not meet the demand of an AI practice.
These gaps with legacy experimentation platforms have already been noted by today's enterprises, who instead opted to create the same in-house tooling, over and over and over again. These in-house tools have become huge investments to maintain even as a down-market forces fiscal prudence.
Companies who are new to investing in AI need a faster, reliable way to achieve AI-grade AB experimentation workflows.