


Databricks has officially launched DBRX, a cutting-edge, open, general-purpose Large Language Model (LLM) that is redefining the benchmarks for open LLMs across the globe. Engineered to surpass the capabilities of GPT-3.5 and match the performance of Gemini 1.0 Pro, DBRX is poised to empower both the open-source community and enterprises with the ability to build their own LLMs, accessing a realm of model API capabilities previously limited to closed systems. Remarkably, DBRX stands out not only for its prowess in general language understanding but also for its specialized performance in programming tasks, where it competes head-to-head with specialized models such as CodeLLaMA-70B.
DBRX's breakthrough is not confined to its capabilities in understanding and programming; it also sets new standards in training and inference efficiency. Through its fine-grained mixture-of-experts (MoE) architecture, DBRX achieves unparalleled efficiency, offering inference speeds up to double that of LLaMA2-70B and requiring only about 40% of the total active parameter count compared to Grok-1. This efficiency extends to its training process, with MoE training showing approximately twice the FLOP-efficiency compared to traditional dense model training methods.
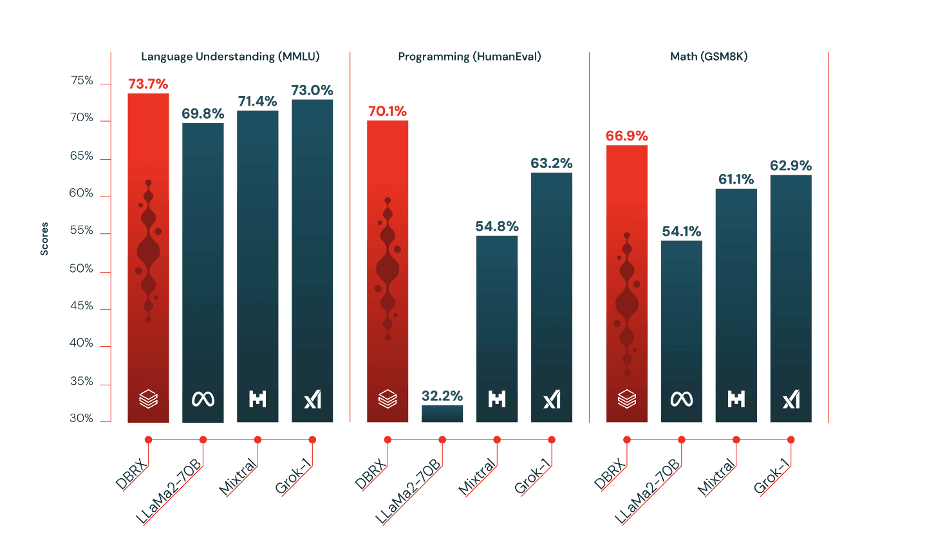
Figure 1: DBRX outperforms established open source models on language understanding (MMLU), Programming (HumanEval), and Math (GSM8K).
The comprehensive development approach of DBRX, encompassing pretraining data, model architecture, and optimization strategy, mirrors the quality of Databricks' previous generation models but at nearly four times less the compute cost. This efficiency positions DBRX as a leader in not only programming and mathematical reasoning but also in language comprehension benchmarks like MMLU, outperforming all known open-source models in these areas.
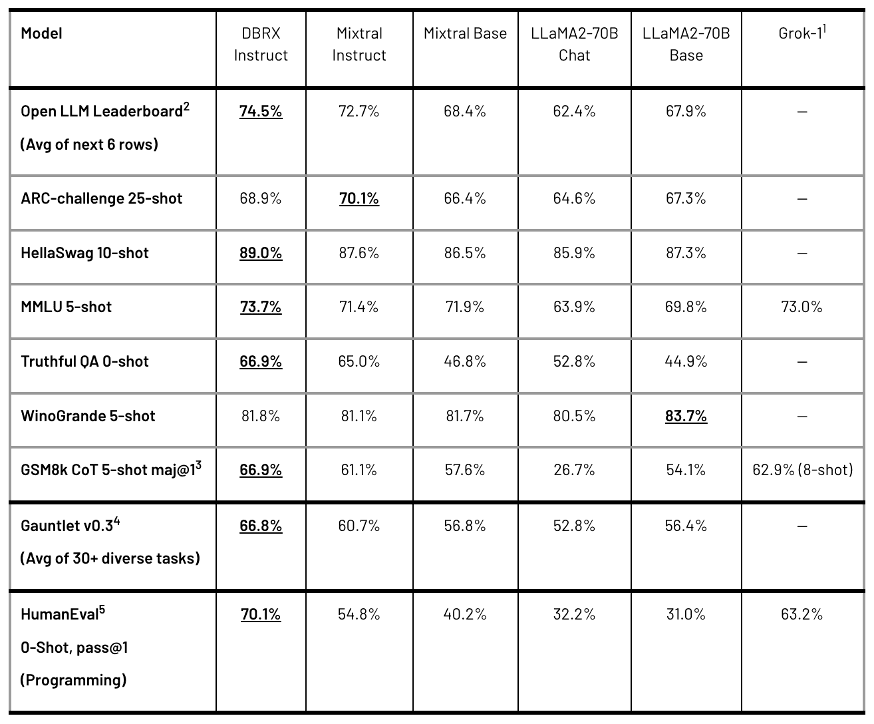
Table 1: Quality of DBRX Instruct and leading open models. See footnotes for details on how numbers were collected. Bolded and underlined is the highest score.
Starting today, DBRX is accessible via APIs to Databricks' customers, marking a significant milestone in democratizing the development of advanced LLMs. For the first time, customers have the opportunity to pre-train their own DBRX-class models from scratch or to enhance existing models using Databricks' cutting-edge tools and methodologies. This integration has already begun to show promising results in applications such as SQL, where DBRX's early deployments are outpacing GPT-3.5 Turbo and pushing the boundaries beyond GPT-4 Turbo's capabilities.
The journey to creating DBRX involved overcoming significant scientific and performance challenges, particularly in training mixture-of-experts models. However, the successful development of a robust training pipeline now enables any enterprise to train world-class MoE foundation models from the ground up. Databricks encourages exploration and utilization of DBRX through its availability on Hugging Face, offering both the base model and fine-tuned versions for various applications.
At its core, DBRX is a decoding-only LLM based on the transformer architecture, designed with a fine-grained MoE architecture. It stands out for its dynamic use of a multitude of small, specialized experts, providing a wide array of possible expert combinations which enhance the model's performance. Pre-trained on a vast dataset of 12 trillion tokens, DBRX's architecture and tokenization strategies have been meticulously optimized to deliver top-tier performance across a wide range of tasks.
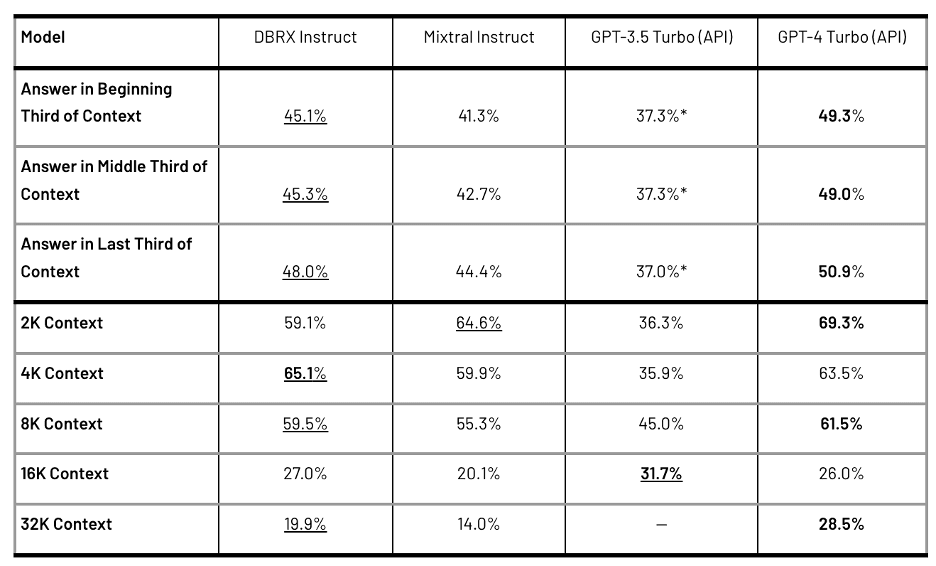 Table 2: Quality of DBRX Instruct and leading closed models. Other than Inflection Corrected MTBench (which we measured ourselves on model endpoints), numbers were as reported by the creators of these models in their respective whitepapers. See footnotes for additional details.
Table 2: Quality of DBRX Instruct and leading closed models. Other than Inflection Corrected MTBench (which we measured ourselves on model endpoints), numbers were as reported by the creators of these models in their respective whitepapers. See footnotes for additional details.
Databricks' commitment to advancing LLM technology is evident in DBRX's development, which leverages a full suite of Databricks tools for data processing, management, and experiment tracking. This holistic approach to model development not only improves the quality of the model but also offers a blueprint for the efficient training of future LLMs.
In comparative analyses against leading open models, DBRX Instruct has emerged as a superior model, excelling in composite benchmarks and specific areas like programming and mathematics. Its ability to outperform and, in some cases, significantly surpass the capabilities of its competitors marks a new era in the development and application of LLMs.
Databricks Sets New Benchmarks with DBRX Instruct: A Comparative Analysis Against Closed Models
In a recent benchmark study, DBRX Instruct, developed by Databricks, has showcased its superior performance over some of the most advanced closed models in the industry, including GPT-3.5, Gemini 1.0 Pro, and Mistral Medium. According to the creators of these models, DBRX Instruct not only exceeds the capabilities of GPT-3.5 but also aligns with the quality of Gemini 1.0 Pro and Mistral Medium across a spectrum of standard benchmarks.
The performance of DBRX Instruct is particularly noteworthy in its comparative analysis against GPT-3.5. It achieves higher scores in critical areas such as the MMLU (73.7% vs. 70%) and HellaSwag (89% vs. 85.5%) benchmarks. The model demonstrates exceptional strength in programming and mathematical reasoning, surpassing GPT-3.5 with scores of 70.1% on HumanEval and 72.8% on GSM8k.
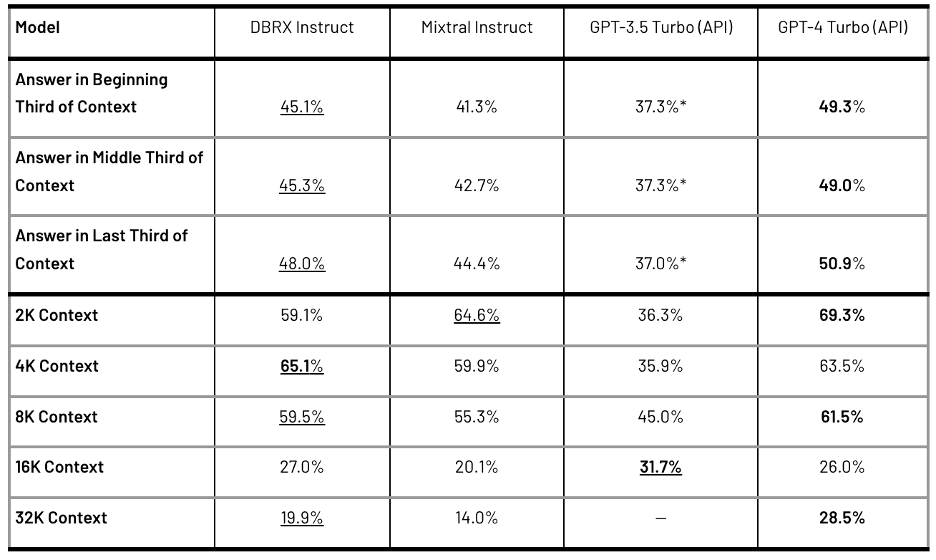 Table 3: The average performance of models on the KV-Pairs and HotpotQAXL benchmarks. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo. GPT-3.5 Turbo supports a maximum context length of 16K, so we could not evaluate it at 32K. *Averages for the beginning, middle, and end of the sequence for GPT-3.5 Turbo include only contexts up to 16K.
Table 3: The average performance of models on the KV-Pairs and HotpotQAXL benchmarks. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo. GPT-3.5 Turbo supports a maximum context length of 16K, so we could not evaluate it at 32K. *Averages for the beginning, middle, and end of the sequence for GPT-3.5 Turbo include only contexts up to 16K.
DBRX Instruct's competitiveness extends to comparisons with Gemini 1.0 Pro and Mistral Medium, where it showcases superior performance in several key benchmarks. It outperforms Gemini 1.0 Pro in Inflection Corrected MTBench, MMLU, HellaSwag, and HumanEval, and exhibits stronger performance in GSM8k. Against Mistral Medium, DBRX Instruct proves to be more effective across various tasks, solidifying its position as a leading model in the field.
Evaluating Long-Context Tasks and RAG Performance
Trained for up to a 32K token context window, DBRX Instruct excels in managing long-context benchmarks, outperforming Mixtral Instruct, GPT-3.5 Turbo, and GPT-4 Turbo APIs. Its performance in KV-Pairs and HotpotQAXL benchmarks, designed for longer sequences, demonstrates its advanced capabilities. In particular, DBRX Instruct surpasses GPT-3.5 Turbo across different context lengths and sequences, closely matching the performance of Mixtral Instruct.
In retrieval-augmented generation (RAG) tasks, DBRX Instruct stands out when analyzing data from a Wikipedia corpus, showcasing its efficacy against Mixtral Instruct, LLaMA2-70B Chat, and GPT-3.5 Turbo. This highlights DBRX Instruct's robustness in leveraging external databases to enhance model responses, a key advantage in complex information retrieval scenarios.
Insights into Training and Inference Efficiency
The efficiency of training and using models like DBRX Instruct is a critical factor for entities aiming to develop foundational models. The mixture-of-experts (MoE) architecture of DBRX significantly enhances compute efficiency, demonstrating the model's ability to achieve high-quality outputs with reduced computational demands. This is evidenced by the training of the MoE-B variant, which achieves notable FLOPs savings while maintaining competitive performance.
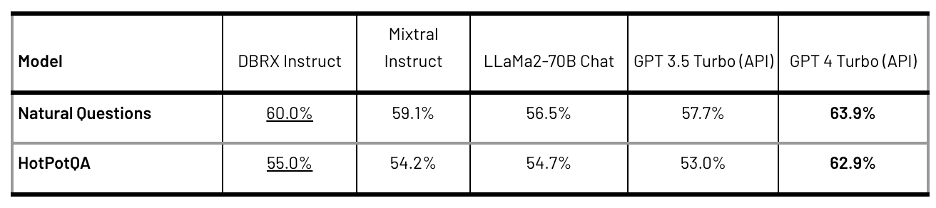
Table 4: The performance of the models measured when each model is given the top 10 passages retrieved from a Wikipedia corpus using bge-large-en-v1.5. Accuracy is measured by matching within the model’s answer. Bold is the highest score. Underlined is the highest score other than GPT-4 Turbo
Databricks' advancements in LLM pretraining have led to a pipeline that is nearly four times more compute-efficient. This improvement is largely attributed to architectural enhancements, optimized strategies, and the quality of pretraining data. The DBRX Dense-A model, benefiting from high-quality data, exemplifies the substantial improvements in model performance with less data, underscoring the effectiveness of Databricks' methodologies.
The inference efficiency, facilitated by an optimized serving infrastructure and demonstrated through NVIDIA TensorRT-LLM, indicates that MoE models can achieve faster throughput compared to traditional models. This efficiency, crucial for handling large volumes of requests, highlights the MoE architecture's potential to balance quality and speed effectively.
Databricks' DBRX Instruct has emerged as a powerful tool in the AI and machine learning landscape, pushing the boundaries of what's possible with large language models. As the technology continues to evolve, the contributions of DBRX Instruct to the field signify a notable advancement in developing and utilizing AI models for complex tasks and applications.











